XMLの構造を分解する:初心者のための要素、属性、名前空間の解説

こんにちは!私の名前はヴオンです。
株式会社メディアフュージョンで、XML関連製品の開発を担当しているベトナム出身のエンジニアです。
XMLに興味のある方や、XMLを利用されている方に、これまでに蓄積してきた経験を共有できればと思っています。
多くの企業システムにおいて、XMLは単なる「< >付きのテキストファイル」ではなく、社内・パートナー企業・第三者プラットフォーム間をつなぐデータ契約の役割を果たしています。
もしこの契約がいい加減に書かれていたら──
- サービスが読み取れない
- データが不整合になる
- デバッグに数日かかる
- そして最悪の場合、業務要件やコンプライアンス違反につながる
これらのミスを避けるためには、エンジニア――開発者であれ、運用担当であれ――が、XMLの基本構造であるルートタグ、要素、属性、名前空間をしっかり理解しておく必要があります。
本記事では文法を丸暗記するのではなく、XMLを体系的に構成されたデータツリーとして捉えることで、将来的にXPath、XSD、XSLT、XQueryを扱う際にも自然に理解でき、「初歩的なミスで頭を抱える」ことがなくなるように解説します。
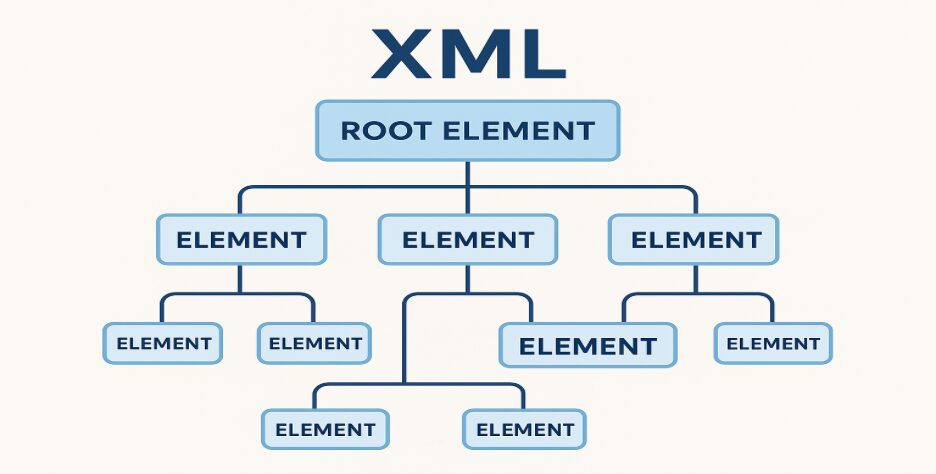
1. XMLは明確なルートを持つツリー構造
すべての正しいXMLドキュメントは次のような特徴を持っています:
- ルート要素(root element)は1つだけ。
- その他のノードは、階層的に入れ子構造(ツリー状)で配置されます。
例:

本質的に見れば、これはツリー構造です。
- order
- Id
- customer → name, email
- items → item → quantity
この見方に慣れれば、以降の記事で扱うクエリ(XPath)、構造検証(XSD)、変換(XSLT)といった概念が非常に論理的に理解できるようになります。
2. XMLの基本となる「ブロック」
2.1: Element(要素):すべての基礎となる存在
要素は開始タグと終了タグのペアで構成されます。

空の要素として記述することもできます。

役割:
- データの意味を表す
- ドキュメントに論理的な構造を与える
2.2. Attribute(属性):付随する情報
属性は開始タグの中に記述されます。

適しているケース:
- ID、コード、ステータス、設定フラグなど
- サブ構造を持たない短い情報
属性に複雑で階層の深いデータを詰め込むのは避けましょう。
読みづらく、検証しづらく、拡張もしにくくなります。
3. ElementかAttributeか?それは設計上の判断であり、「好み」で決めるものではありません。
よくある設計ミスのひとつが、「気分でattributeにしたり、elementにしたりする」ことです。
実務的な原則:
次のような場合はelementを優先しましょう:
- それが主要なデータである
- 次のような可能性がある
- サブ要素を追加する
- 複数回繰り返す
- 独自のスキーマで制約を設ける
非効率な設計例:

より良い設計:

Attributeを優先する場合:
- ID、コード、ステータス、種類、バージョン
- 通常はメタデータで、サブ構造を必要としないもの

4. Namespace – 複数の標準が共存する場合の鍵
企業環境では、1つのXMLドキュメントに以下が混在することがあります:
- 業界標準(例:請求書標準、医療標準)
- 会社独自の拡張
- 他システム向けのメタデータ
Namespaceがないと、名前の衝突が発生しやすくなります。

4.1. 基本的な宣言方法

ここでは:
- URI http://example.com/invoice は論理的な識別子であり、必ずしも内容を返すURLである必要はありません。
- このnamespaceに属するすべてのタグは、名前が同じでも他のnamespaceと明確に区別されます。
4.2. Namespaceでよくある間違い
- URIを気まぐれに変更 → 検証ツール、XPath、XSLTがすべて壊れる
- Namespaceを宣言したが使わない、またはプレフィックスがスキーマと一致しない
- デフォルトNamespaceを理解していない → XPath/XSDを書いてもノードにマッチしない
記事1では、「JSONが普及しているにも関わらず、なぜXMLが大規模システムで使われ続けているのか?」という問いに答えました。
記事2の目的は、XMLの構造を正しく理解し、規律ある設計を行うことです。
もし次のことをしっかり理解できれば:
- XMLは明確なルートを持つツリー構造である
- ElementとAttributeを区別できる
- Namespaceを正しく使える
次のステップ、例えばXSDによるスキーマ定義、バリデータでのデータ制御、XPath/XSLTによるクエリも自然に理解でき、「XMLは複雑で扱いにくいもの」という印象はなくなります。
次回の記事では、XSDと「well-formed ≠ valid」の話に入り、今日学んだ設計ルールを自動チェックのルールに変換し、どのシステムでも信頼して使えるようにしていきます。