Enterprise BIその2、Power BIのFabric OneLakeの有効な場面とは
こんにちは!フォンと申します。
株式会社メディアフュージョンのPower BI関連製品の開発を担当しているベトナム出身のエンジニアです。
蓄積された経験をPower BIに興味のあるや利用者などに共有したいです。
Microsoft FabricのDirect Lakeは、従来のImport Modeと比較してデータ更新時間を約2.5倍高速化(50万行で実測)。
レポート描画速度はImportと同等。ただし計算列やRLSに制約があり、すべてのケースでImportより優れるわけではありません。
大規模データで更新頻度が高いシナリオに最適です。
SharePoint上のExcel/CSVをPower BIのImport Mode(※ データソースから全データをメモリにコピーし、圧縮して保持する従来の方式)で取り込む構成は、多くの企業が採用している定番のパターンです。
シンプルで導入しやすい。しかし、データ量が50万行を超えたあたりから、私たちのチームでも「このままで大丈夫か?」という声が上がり始めました。
Microsoft Fabricの登場で、「Direct Lake」という新しいストレージモードが選択肢に加わりました。本当に速いのか?どこが違うのか?
本記事では、私たちが実際に50万行のデータで検証した結果と、そこから見えてきた「Direct Lake」が有効な場面」をお伝えします。
私たちが抱えていた課題
私たちのチームでは、以下のワークフローでBI基盤を運用していました。
Power Automate → JSON → SharePoint → Power BI (Import Mode)
APIへの過剰アクセスを避けつつ、定期的にデータを更新する構成です。数万行のうちは問題ありませんでした。
しかし、データ量が50万行に達したころから、状況が変わり始めました。
- リフレッシュに23秒—Power BI Proでは1日8回・各1回と2時間の制限があります(Fabricライセンスでは大幅に緩和)
- メモリ消費の増大—Import Modeでは全データをメモリにコピーするため、データ量に比例して負荷が増える
- SharePointのファイルサイズ制限への接近
構成の変化:ビフォー/アフター
| ビフォー(従来構成) | アフター(Fabric構成) |
|---|---|
| Power Automate → JSON → SharePoint → Power BI (Import) | データソース → Dataflow Gen2 → OneLake → Direct Lake |
| 更新:全データを再コピー(23秒) | 更新:メタデータのみ(9秒) |
| Power Query経由でデータ取得 | Power Query不要、Deltaテーブル直接参照 |
そもそもDirect Lakeとは何か
Power BIのストレージモードは、2つのカテゴリに分かれます。
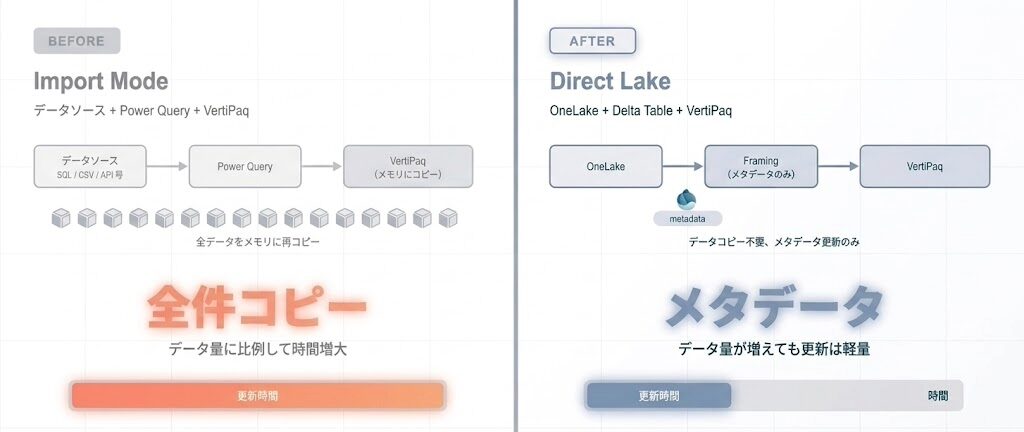
Import Modeは、Power Query(※ さまざまなデータソースからデータを取得・整形するためのETLツール。Excel感覚でデータ加工が可能)を使ってデータをメモリに読み込み、VertiPaqエンジンで(※ Power BIが内部で使用する高速圧縮エンジン。データを列単位で圧縮し、高速なクエリ処理を実現する)圧縮・保持する方式です。クエリが速い反面、データの鮮度はリフレッシュ頻度に依存します。
DirectQuery / Direct Lakeは、いずれもPower Queryを介さずにデータソースから直接データを取得する「直接接続系」のモードです。
Direct Lakeは、OneLake(※ Microsoft Fabricが提供する統合データレイク。組織内のすべてのデータを一元管理する「単一の湖」として機能する)上のDeltaテーブル(※ データの変更履歴を自動管理するオープンソースのテーブル形式。どのファイルが最新かをメタデータで追跡できる)を直接参照しつつ、VertiPaqエンジンを使ってクエリを実行します。データをコピーせず、かつクエリが速い。それがDirect Lakeの特徴です。
| # | Import Mode | DirectQuery | Direct Lake |
|---|---|---|---|
| カテゴリ | インポート系 | 直接接続系 | 直接接続系 |
| Power Query | 使用する | 使用しない | 使用しない |
| データ配置 | メモリにコピー | 元DBに都度接続 | OneLake直接参照 |
| クエリエンジン | VertiPaq | ソースDB依存 | VertiPaq |
| クエリ速度 | 高速 | DB性能依存 | 高速(Import同等) |
| データ鮮度 | リフレッシュ依存 | リアルタイム | 準リアルタイム |
| データ更新 | 全データ再コピー | 不要 | メタデータのみ(数秒) |
Import Modeの強みを見落とさない
Direct Lakeが注目されていますが、Import Modeには独自の強みがあります。
- 計算列・計算テーブルが自由に使える—ビジネスロジックの埋め込みが柔軟
- セルフサービスアナリストが素早く動ける—Power Queryのデータ整形がそのまま使える
- Fabricライセンス不要—Power BI Proだけで完結し、コストが低い
- データ量が小さければ、クエリ速度は最速—VertiPaqの圧縮が最も効率的に機能する
重要なポイント:Direct Lakeは「Importの上位互換」ではなく、大規模データ向けに最適化された別モードと捉えるのが正しい評価です。
なぜDirect Lakeは更新が速いのか
Import Modeのリフレッシュは、データ全体をPower Queryで読み込み、VertiPaqがメモリ上に圧縮・展開する処理です。データ量が大きいほど、この工程に時間がかかります。
一方、Direct Lakeの更新処理は「フレーミング(Framing)(※ Direct Lake独自の更新処理。Deltaテーブルの「どのファイルが最新か」というメタデータだけを読み取る軽量な操作)」と呼ばれ、Deltaテーブルのメタデータ(どのファイルが最新か)だけを読み取ります。データ本体のコピーは発生しません。これが、更新が数秒で完了する理由です。
レポートを開いたときの描画速度については、Direct LakeもImport Modeも同じVertiPaqエンジンを使用するため、同等のパフォーマンスが得られます。
補足:初回アクセス時(Cold Cache(※ データがまだメモリに読み込まれていない状態。初回アクセス時がこれに該当する))には、Delta形式からVertiPaq形式へのTranscoding処理(※ Delta形式のデータをVertiPaqが読み取れる形式に変換する処理。Cold Cache時にのみ発生する)が発生します。2回目以降(Warm Cache(※ キャッシュが効いている状態。2回目以降のアクセスではImport Modeと同等速度になる))はキャッシュが効き、Import Modeと同等の速度になります。
実測検証:50万行での比較
50万行の売上データを使い、データ更新にかかる時間を比較しました。
データ更新時間の比較
| 方式 | 更新時間 | 差 |
|---|---|---|
| SharePoint + Import Mode | 23秒 | 基準 |
| OneLake + Direct Lake | 9秒 | 約2.5倍高速 |
Import Modeの23秒は、Power Queryによる読み込みとVertiPaqによる圧縮処理の合計です。Direct Lakeの9秒は、フレーミング(メタデータ更新)のみ。データ量がさらに増えた場合、この差はより顕著になります。
レポート描画速度について
レポートを開いたときのビジュアル表示速度は、Direct LakeもImport ModeもVertiPaqエンジンを使うため、ほぼ同等です。DirectQuery(※ データをコピーせず、元のデータベースに都度クエリを発行するモード。リアルタイム性は高いが、速度はDB性能に依存する)はソースDBに都度クエリを発行するため、一般的には最も遅くなります。
導入前に知っておくべき制限事項
Direct Lakeには以下の技術的な制約があります。
- Direct Lakeテーブル上の計算列・計算テーブルは使用不可—Lakehouse側で事前に準備が必要。ただし、複合モデル内のImportテーブルでは計算列が使用可能
- RLS(行レベルセキュリティ)(※ ユーザーごとに表示できるデータ行を制限するセキュリティ機能)使用時はDirectQueryにフォールバックし、パフォーマンスが低下する可能性
- 複合モデル(Direct Lake + Import)はプレビューとして利用可能—大規模ファクトはDirect Lake、小規模ディメンションはImportという使い分けが可能に
- Cold Cache時にTranscoding処理が発生。初回のみ描画に若干時間がかかる
OneLakeへのデータ取り込み方法
OneLakeへのデータ取り込みは、Dataflow Gen2(※ Microsoft Fabric上で動作するデータ取り込みツール。Power Queryと同じ操作感でデータの収集・変換が可能)を使ってデータソースから直接収集するのが正攻法です。
データソース → Dataflow Gen2 → OneLake → Direct Lake
Dataflow Gen2はFabricワークスペース内で動作し、既存のPower Queryの知識がそのまま活かせるのも利点です。
まとめ:ImportとDirect Lake、どちらを選ぶか
最後に、判断のフレームワークを整理します。
| 観点 | Import Mode | Direct Lake |
|---|---|---|
| データ量 | 小〜中規模に最適 | 中〜大規模に最適 |
| 更新頻度 | 低〜中(日次・週次) | 高頻度に強い(メタデータ更新) |
| 計算の自由度 | 高い(計算列・テーブル自由) | 制約あり(計算列や一部のモデリング機) |
| 運用コスト | 低い(Proのみで完結) | Fabricライセンスが必要 |
| データ基盤の成熟度 | 低くてもOK(セルフサービス向き) | Lakehouse/DWHの知識が必要 |
Direct Lakeは「Importの上位互換」ではなく、
大規模データ向けに最適化された別モードと捉えるのが正しい。
次回の記事(その3)では、「SharePointベースで十分なケース」と「OneLake/Fabricが必要になるケース」を整理し、コスト比較と段階的な移行ロードマップをご紹介します。
関連サービス・導入支援
株式会社メディアフュージョンでは、Power BIに関する以下のサービスを提供しています。
データ分析(Power BIソリューション)
提供内容:
DXコンサルティング/サポート
提供内容:
参考文献
https://learn.microsoft.com/ja-jp/fabric/fundamentals/direct-lake-overview
https://learn.microsoft.com/ja-jp/fabric/onelake/onelake-access-api
https://datacrafters.io/fabric-direct-lake-vs-import-vs-directquery