レコード型とは、Power Query Mにおけるレコードの一般的な変換
こんにちは!フォンと申します。
株式会社メディアフュージョンのPower BI関連製品の開発を担当しているベトナム出身のエンジニアです。
蓄積された経験をPower BIに興味のあるや利用者などに共有したいです。
Power Queryの特徴は、テーブルのフィールド(列)の中に構造を持ったデータを定義でき、構造化データを一つの値として扱えることです。
前回の記事で説明したリスト型のデータもテーブルの一つのフィールドに配置できます(より強力なデータ変換のために Power Query M リストを理解する)。テーブルのフィールドにはテーブルも定義することが出来ます。これが出来ることにより、データ処理の幅がずいぶん広がります。
例えば、20枚のシートがあるExcelのBookをPower Queryに読込んだとします。まず、1シート1レコードのテーブルが出来ます。各レコードにはシート名などのフィールド他にシートをテーブルとして読込んだ一つのフィールドが自動的に定義されています。
今回は前回に引き続き、構造化型のデータの扱いについてポイントを説明します。今回はレコードです。
Power Queryを操作すると上述したようにテーブル型のフィールドが自動生成されることがよくあります。このテーブル型のフィールドを操作しなければ目的の分析用テーブルが作れません。そんな場合に、「リスト」と並んで「レコード」を扱う機会が出てきます。
レコード(型)とは
レコードは、複数の要素(値)で構成され、リストと異なりそれぞれの要素に名前が定義された構造です。 これらの要素はフィールドと呼ばれます。
レコードは、テーブルの1行分と考えてもらえばいいかと思います。
例: 人の個人情報を表すレコードは、氏名、生年月日、電話番号、住所などのフィールドが含まれます。
フィールドに設定されるデータは、文字や数字などの値だけでなく、リスト型やレコード型のような構造化データの場合もあります。
次に、レコードを操作するときの基本的な操作をいくつか紹介します。
レコードを作成する
左角括弧と右角括弧を使用してレコードを作成します: [ ]
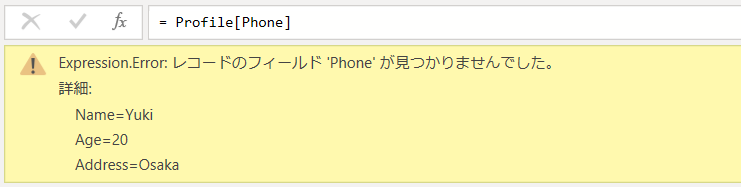
例:[ Name = “Yuki”, Age = 20, Address= “Osaka” ]

この例では、 Name 、 Age 、 Address がキー (フィールド名) です。Yuki、20、Osaka はそれぞれの値です。
レコードでは、3 つのキーと値のペアがカンマで区切られ、ステートメントが角括弧で囲まれています。
フィールド名について
文字間にスペースが含まれる場合があります。
フィールド名に特殊文字が含まれる場合先頭に「#」 を付けて“”で囲む必要があります。

注: レコードフィールド名は、重複せず一意でなければなりません。
上記の作成方法に加えて、Power Queryには、リストやテーブルからレコードを作成するための関数も多数用意されています。
Record.FromList: フィールド値のリストとフィールドのセットを含むレコードを返します。
Record.FromTable: フィールド名と値名を含むレコードのテーブルからレコードを返します。
行を参照する操作は、次の構文を使用してレコードも返します。
Table{row_index_number}
インデックスは0 から始まり、1 単位ずつ増加します。
フィールドにアクセス
レコード内のフィールドにアクセスしてそのデータを操作するには、次の構文を使用します。
RecordName[FieldName]

あるいは、Record.Field 関数を使用してフィールドにアクセスすることも出来ます。
注: 存在しないフィールド名を取得すると、エラーが生成されます。
テーブル内のレコード構造化データ列を展開します。
使用するデータ ソースによっては、取得してテーブルに変換した後、レコード、リスト、テーブルなどの構造化データ列が表示されることがよくあります。つまり、作業に必要なデータを取得するには、これらのデータ列を展開する必要があります。
この記事では、次のリンクにある json のサンプル データ ソースを使用して説明します。
https://dummyjson.com/users
最初に、Power BI Desktop で利用可能な Web コネクタを使用してデータを読み込みました。 データが取得されると、自動的に処理され、最終的なデータ テーブルに出力されます。ただし、これらのデータ処理ステップのPower Query コードを見ると、ああ、とても長くて理解するのが難しいと感じるでしょう。詳しく見てみると、主にレコード構造を持つデータ列を展開しています。
次の図は、UI 画面の操作でレコード データの列を展開する方法を示しています。
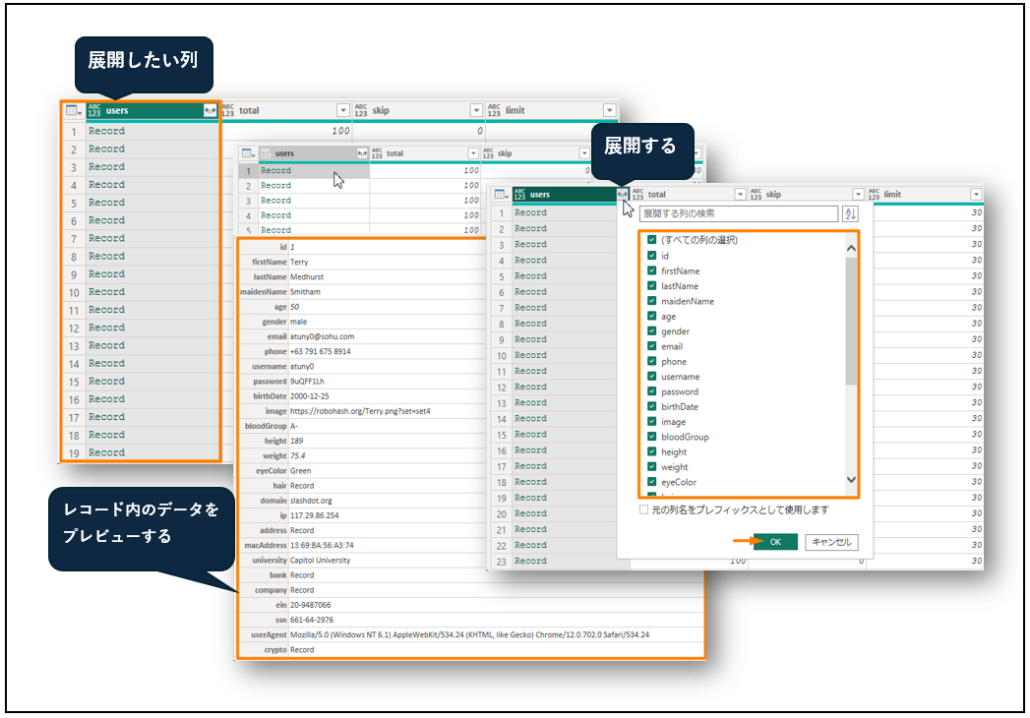
この操作の自動生成されたPower Query M コードを確認すると、次のようになります。Table.ExpandRecordColumn 関数が使用されました。
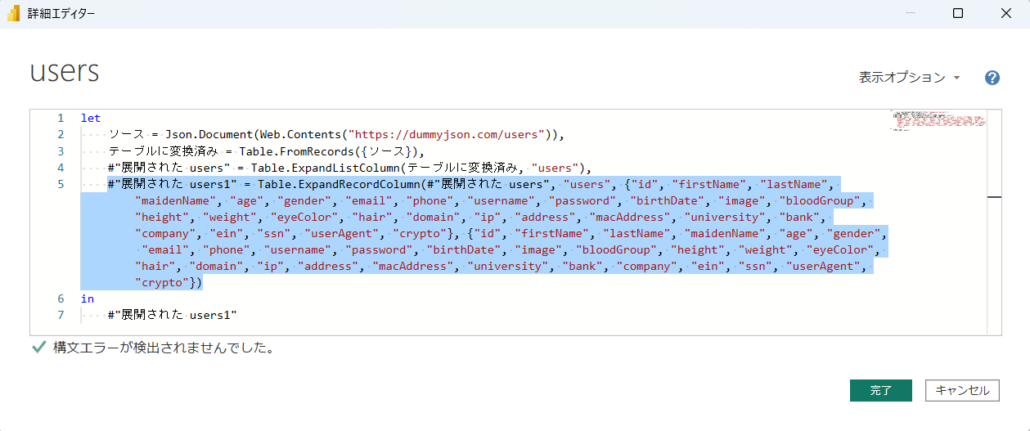
ここでの問題は、フィールド名のリストと展開後の 列名のリストが固定されていることです。
データ ソースに変更がある場合、新しいフィールドの追加など、そのフィールドは拡張リストに存在しないのでデータが失われますあるいは旧フィールドが削除されてもフィールドリストにまだ存在するため、依然として出力に 反映され、混乱が生じます。
解決策は、固定する代わりに、レコードのすべてのフィールド名を含むリストを取得するPower Query コードを作成し、そのリストを展開関数の引数に渡す。
let
ソース = Json.Document(Web.Contents("https://dummyjson.com/users")),
テーブルに変換済み = Table.FromRecords({ソース}),
#"展開された users" = Table.ExpandListColumn(テーブルに変換済み, "users"),
//users列の最初の行にあるレコードのすべてのフィールド名を取得します。
#"フィールド名 リスト" = Record.FieldNames(#"展開された users"{0}[users]),
#"展開された users1" = Table.ExpandRecordColumn(#"展開された users", "users", #"フィールド名 リスト", #"フィールド名 リスト")
in
#"展開された users1"
※プラス
実際には、各レコードが常に同じ固定フィールド名を持つとは限りません。その後、テーブルの展開に使用されるフィールド名のリストを取得するために最初のレコードを参照すると、データ損失が発生する可能性があります。
この場合、すべてのレコードを反復処理して各レコードのフィールド名のリストを取得し、重複を削除し、列名の一意のリストを作成します必要があります。
// 列内のすべての行を反復して、列名の一意のリストを作成します
#"フィールド名 リスト" = List.Distinct(List.Combine(List.Transform(#"展開された users"[users], each Record.FieldNames(_)))),
しかし、レコード数が多すぎる場合、この方法は処理に時間がかかるため効果的ではありません。パフォーマンスを確保するために出力列名を固定することを検討する必要がある場合があります。

